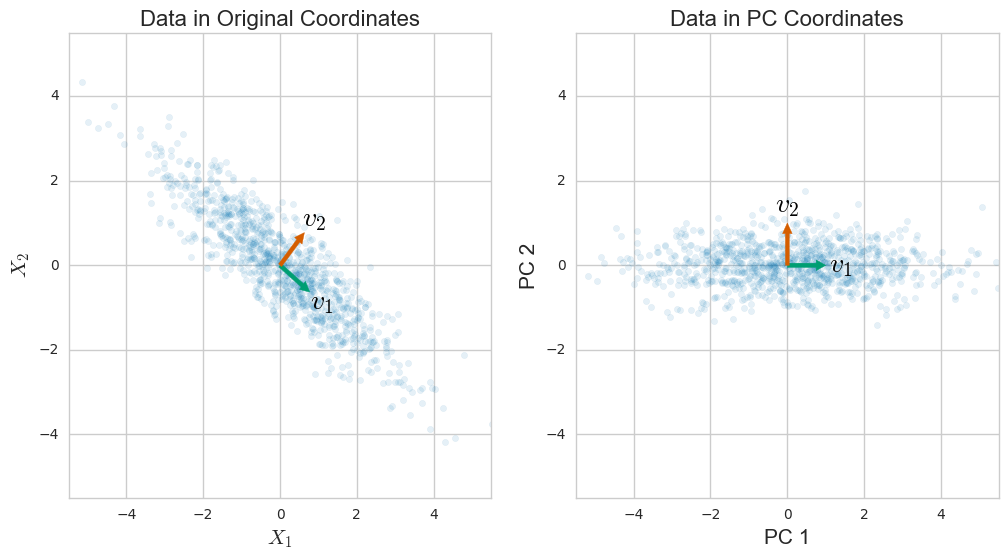
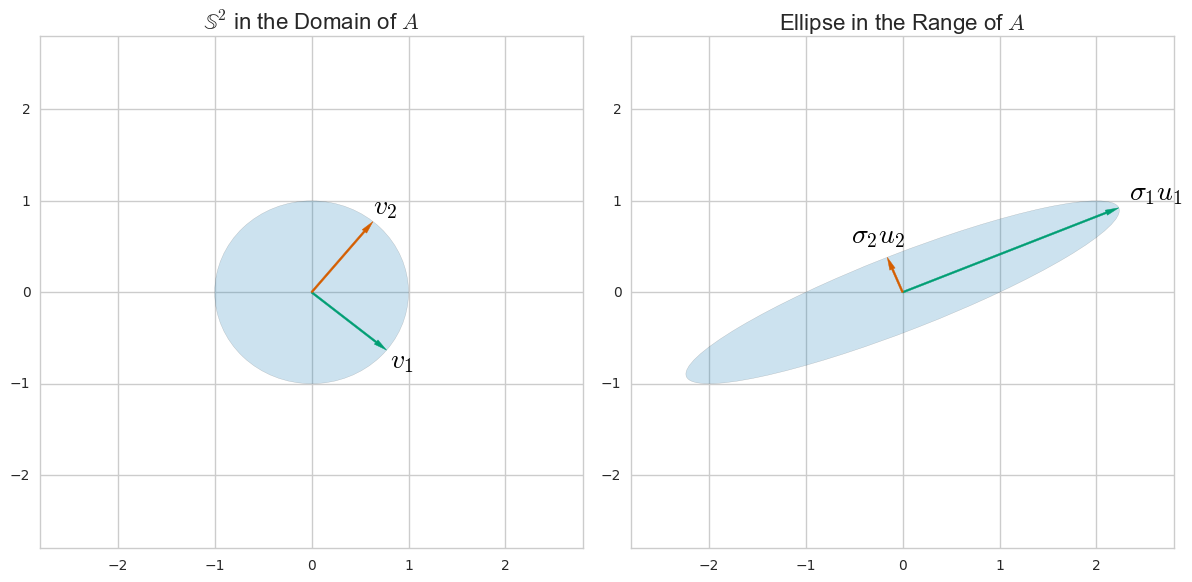
Analiza głównego składnika (PCA) jest zwykle wyjaśniana za pomocą rozkładu własnego macierzy kowariancji. Jednakże, można także przeprowadzić za pomocą rozkładu wartości pojedyncza (SVD) macierzy danych . Jak to działa? Jaki jest związek między tymi dwoma podejściami? Jaki jest związek między SVD a PCA?
Lub innymi słowy, jak użyć SVD matrycy danych do przeprowadzenia redukcji wymiarowości?
8
Napisałem to pytanie w stylu FAQ wraz z własną odpowiedzią, ponieważ jest ono często zadawane w różnych formach, ale nie ma kanonicznego wątku, a zatem zamykanie duplikatów jest trudne. Podaj meta komentarze w tym towarzyszącym meta wątku .
—
ameba
Oprócz doskonałej i szczegółowej odpowiedzi ameby z jej dalszymi linkami, mogę zalecić sprawdzenie tego , gdzie PCA jest rozważane obok innych technik opartych na SVD. Dyskusja przedstawia algebrę prawie identyczną z amebą, z niewielką różnicą, że mowa tam, opisująca PCA, dotyczy rozkładu svd z [lub ] zamiast - co jest po prostu wygodne, ponieważ odnosi się do PCA wykonanego przez składową macierz kowariancji. X/ √ X
—
ttnphns
PCA jest szczególnym przypadkiem SVD. PCA potrzebuje znormalizowanych danych, najlepiej tej samej jednostki. Matryca to nxn w PCA.
—
Orvar Korvar
@OrvarKorvar: O jakiej macierzy nxn mówisz?
—
Cbhihe