Ken streścił już niektóre powody swojej odpowiedzi . Aby rozwinąć to dalej
Oczywiście większe pamięci podręczne potrzebują więcej tranzystorów. Ale przy większej liczbie tranzystorów mamy również możliwość użycia szybszych pamięci podręcznych . Pamięć podręczna procesora to po prostu SRAM, która zazwyczaj składa się z 6 tranzystorów (AKA 6T SRAM). Jednak gdy jest wystarczająca liczba tranzystorów, warto użyć szybszych, ale większych komórek SRAM wykonanych z więcej niż 6 tranzystorów (takich jak 8T, 10T SRAM)
- Więcej instrukcji SIMD , które przetwarzają się szybciej niż instrukcje z pojedynczymi danymi
Nie tylko SIMD, ale wszelkiego rodzaju instrukcje przyspieszające. Na przykład współczesne architektury często mają jednostkę AES dla szybszego szyfrowania / deszyfrowania, FMA dla lepszego obliczeń matematycznych (zwłaszcza cyfrowego przetwarzania sygnałów) lub wirtualizację dla szybszych maszyn wirtualnych. Obsługa większej liczby instrukcji oznacza, że do ich odkodowania i wykonania potrzeba więcej zasobów
- Więcej rdzeni , dzięki czemu możesz robić dwie lub więcej rzeczy jednocześnie
- Rurociągi , dzięki czemu każdy rdzeń może robić więcej rzeczy naraz
Te są całkiem jasne
- Jednostki bardziej funkcjonalne, takie jak wbudowany w FPU s, a wielokrotność ALU s
W przeszłości nie było wystarczającej powierzchni matrycy dla FPU, więc ludzie muszą kupić osobny, jeśli mają wysokie wymagania arytmetyki zmiennoprzecinkowej. Przy znacznie większej liczbie tranzystorów możliwe jest wbudowanie FPU, co znacznie przyspiesza matematykę zmiennoprzecinkową
Poza tym współczesne procesory są superskalarne i będą próbowały robić wiele rzeczy naraz , znajdując niezależne elementy danych i obliczając je wcześniej, mimo że strumień instrukcji jest liniowy i szeregowy. Im więcej rzeczy mogą robić równolegle, tym szybciej będą. Aby to zrobić, procesor może mieć wiele jednostek ALU, a jednostka ALU może mieć wiele jednostek wykonawczych. Jeśli na przykład procesor ma 5 sumatorów w porównaniu do 4 w poprzedniej generacji, to działa już o 25% szybciej w najbardziej optymistycznej sytuacji bez żadnych zmian zegara. Bardziej zaawansowane procesory wykorzystują nawet wykonywanie zadań poza kolejnością (co ma miejsce w przypadku większości nowoczesnych procesorów o wysokiej wydajności)
Operacje można zazwyczaj wykonywać na różne sposoby. Jeśli masz więcej tranzystorów, będziesz mieć więcej zasobów, aby użyć szybszej techniki. Kilka prostych przykładów:
Przesunięcie bitów:
Prosta manetka jest przez podłączenie szeregowo przerzutników razem.

To wymaga tylko jednego przerzutnika na bit, a zatem niezwykle kompaktowego. Ale potrzebuje jednego zegara, aby przesunąć bit w lewo lub w prawo. Dlatego mikrokontrolery i małe wbudowane procesory mają tylko instrukcje, aby przesuwać się o jeden. Widzieć
Gdy masz więcej tranzystorów do wydania, możesz zmienić na lufę . Teraz procesor może przesuwać bity w jednym zegarze kosztem setek lub tysięcy tranzystorów
Dodanie:
- Prosty sumator jest także tworzony przez łączenie pełnych sumatorów szeregowo. W ten sposób dodatek N-bitowy potrzebuje N zegarów, aby zakończyć swoją pracę, co z pewnością nie jest tym, czego ludzie oczekują od procesora
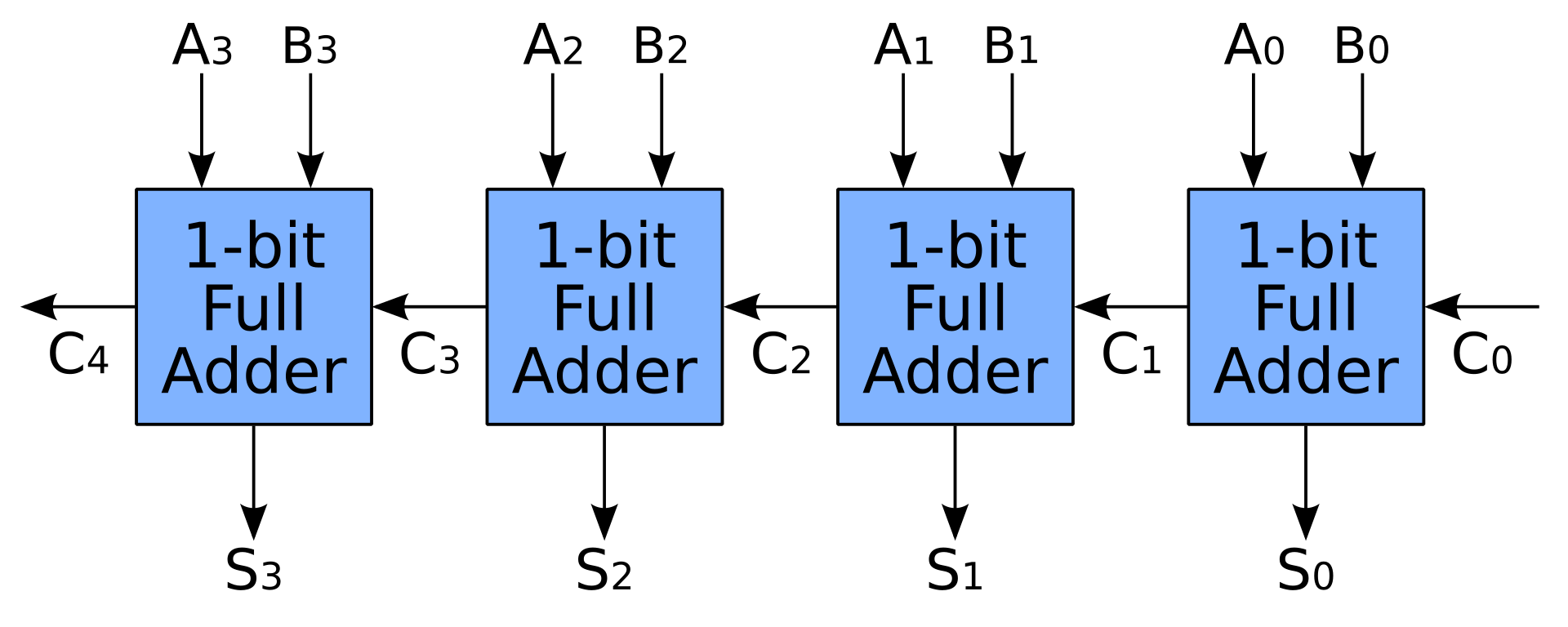
- Przy większej liczbie tranzystorów możemy przyspieszyć dodawanie, wstępnie obliczając przeniesienia za pomocą przeniesienia lookahead lub sumy przeniesienia . Pełne sumatory są nadal używane, ale potrzeba więcej miejsca na jednostkę przenoszenia wstępnego
To samo dotyczy innych jednostek, takich jak mnożniki, dzielniki, harmonogram ... Na przykład możemy wykonać mnożenie bardzo szybko w jednym zegarze, używając logiki kombinacyjnej . Możesz zobaczyć kilka prostych przykładów w pytającym mnożniku 3-bitowym - jak one działają? . Ale potrzebne tranzystory wzrosną do kwadratu szerokości wejściowych, dlatego małe procesory z multiplikatorem używają logiki sekwencyjnej, aby zaoszczędzić dużo miejsca na multiplikator:
Starsze architektury multiplikatorów wykorzystywały przesuwnik i akumulator do sumowania każdego produktu częściowego, często jednego produktu częściowego na cykl, zmniejszając prędkość dla obszaru matrycy. Nowoczesne architektury multiplikatorów wykorzystują (zmodyfikowany) algorytm Baugh – Wooleya, drzewa Wallace'a lub multiplikatory Dadda, aby dodać produkty częściowe w jednym cyklu. Wydajność implementacji drzewa Wallace jest czasem poprawiana przez zmodyfikowane kodowanie Booth jednego z dwóch multiplikatów, co zmniejsza liczbę częściowych produktów, które należy zsumować
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
Gdy masz już ogromną pulę tranzystorów, możesz nawet użyć logiki kombinacyjnej, aby wykonać FMA, która wymaga znacznie więcej zasobów niż mnożnik
Nowoczesne komputery mogą zawierać dedykowany MAC, składający się z multiplikatora zaimplementowanego w logice kombinacyjnej, po którym następuje sumator i rejestr akumulatorów, który przechowuje wynik. Wyjście rejestru jest przekazywane z powrotem do jednego wejścia sumatora, dzięki czemu w każdym cyklu zegarowym wyjście wzmacniacza jest dodawane do rejestru. Mnożniki kombinacyjne wymagają dużej logiki, ale mogą obliczać produkt znacznie szybciej niż metoda przenoszenia i dodawania typowa dla wcześniejszych komputerów.
Operacja wielokrotnego gromadzenia

#/media/File:1-bit_full-adder.svg)