W swojej pracy w autoencoders do klasyfikacji tekst Hinton i Salakhutdinov wykazały wykres wytwarzanego przez 2 wymiarowe LSA (co jest ściśle związane z PCA) 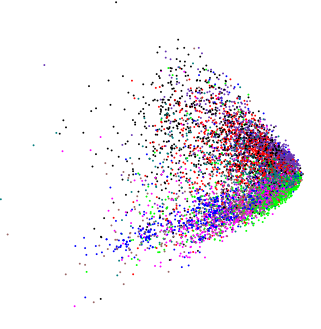 .
.
Stosując PCA do absolutnie różnych nieco nieco wymiarowych danych, otrzymałem podobnie wyglądający wykres:  (z wyjątkiem tego przypadku naprawdę chciałem wiedzieć, czy jest jakaś struktura wewnętrzna).
(z wyjątkiem tego przypadku naprawdę chciałem wiedzieć, czy jest jakaś struktura wewnętrzna).
Jeśli wprowadzimy losowe dane do PCA, otrzymamy kroplę w kształcie dysku, więc ten kształt w kształcie klina nie jest losowy. Czy to samo coś znaczy?
6
Zakładam, że wszystkie zmienne są dodatnie (lub nieujemne) i ciągłe? Jeśli tak, krawędzie klina są tylko punktami, powyżej których dane stałyby się 0 / ujemne. Co więcej, możesz uzyskać ten sam wzór, który wyświetlasz z dodatnimi zmiennymi o skośnych prawych; obserwacje są skupione w dolnej części. Gdybyś miał dodatnie jednolite zmienne losowe, zobaczyłbyś (obrócony) kwadrat. Dlatego wzorce, takie jak ten, który wyświetlasz, są tylko ograniczeniami danych. Mogą pojawiać się inne wzorce, jak podkowa, ale nie są to spowodowane ograniczeniami zakresów zmiennych.
—
Gavin Simpson
@GavinSimpson To znacznie więcej niż komentarz. Dlaczego nie rozwinąć go w odpowiedź?
—
Mike Hunter,
Zapytałem moje dzieci (3 i 4 lata), co przypominają im te zdjęcia, i powiedzieli, że to ryba. Więc może „kształt ryby”?
—
ameba
@GavinSimpson, dzięki! W obu przypadkach zmienne są rzeczywiście nieujemne, bot również w obu przypadkach są wartościami całkowitymi. Czy to coś zmienia?
—
macleginn







