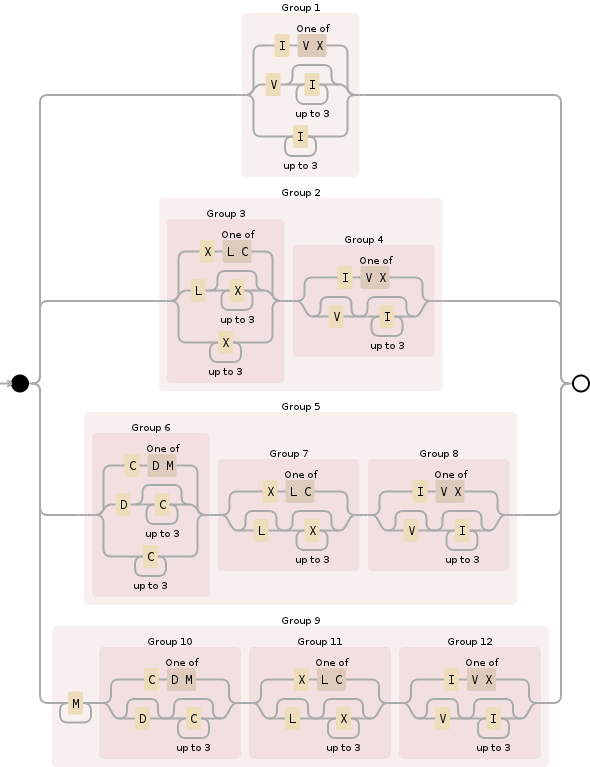
Możesz użyć do tego następującego wyrażenia regularnego:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Rozbijając go, M{0,4}określa sekcję tysięcy i zasadniczo ogranicza go do między 0a 4000. To stosunkowo proste:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Możesz oczywiście użyć czegoś w rodzaju, M*aby zezwolić na dowolną liczbę (w tym zero) tysięcy, jeśli chcesz zezwolić na większe liczby.
Dalej (CM|CD|D?C{0,3}), nieco bardziej skomplikowane, dotyczy sekcji setki i obejmuje wszystkie możliwości:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Po trzecie, obowiązuje (XC|XL|L?X{0,3})te same zasady, co poprzednia sekcja, ale dla miejsca dziesiątek:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
I wreszcie, (IX|IV|V?I{0,3})jest sekcja jednostki, obsługa 0przez 9i podobne do dwóch poprzednich odcinków (cyfry rzymskie, pomimo ich pozornej tajemniczości, przestrzegać pewnych reguł logicznych Po dowiedzieć się, jakie są):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Pamiętaj tylko, że to wyrażenie regularne będzie również pasowało do pustego ciągu. Jeśli tego nie chcesz (a Twój silnik wyrażeń regularnych jest wystarczająco nowoczesny), możesz zastosować pozytywne spojrzenie w tył i w przyszłość:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(inną alternatywą jest po prostu sprawdzenie, czy długość nie wynosi wcześniej zero).