Mam to pytanie od miesięcy. Wygląda na to, że po prostu sprytnie odgadliśmy softmax jako funkcję wyjściową, a następnie interpretujemy dane wejściowe do softmax jako log-prawdopodobieństwa. Jak powiedziałeś, dlaczego po prostu nie znormalizować wszystkich wyników, dzieląc je przez ich sumę? Znalazłem odpowiedź w książce Deep Learning autorstwa Goodfellow, Bengio i Courville (2016) w sekcji 6.2.2.
Powiedzmy, że nasza ostatnia ukryta warstwa daje nam z jako aktywację. Następnie softmax definiuje się jako

Bardzo krótkie wyjaśnienie
Exp w funkcji softmax z grubsza anuluje logarytm utraty entropii krzyżowej, powodując, że strata jest mniej więcej liniowa w z_i. Prowadzi to do mniej więcej stałego gradientu, gdy model jest nieprawidłowy, co pozwala na szybką korektę. Zatem źle nasycony softmax nie powoduje zanikania gradientu.
Krótkie wyjaśnienie
Najpopularniejszą metodą uczenia sieci neuronowej jest oszacowanie maksymalnego prawdopodobieństwa. Szacujemy parametry theta w sposób maksymalizujący prawdopodobieństwo danych treningowych (o rozmiarze m). Ponieważ prawdopodobieństwo całego zbioru danych uczących jest iloczynem prawdopodobieństw każdej próbki, łatwiej jest zmaksymalizować prawdopodobieństwo logarytmiczne zbioru danych, a tym samym sumę prawdopodobieństwa logarytmicznego każdej próbki indeksowanej przez k:
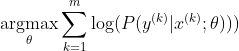
Teraz skupiamy się tylko na softmax z już podanym z, więc możemy wymienić
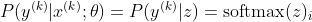
gdzie i jest poprawną klasą k-tej próbki. Teraz widzimy, że kiedy weźmiemy logarytm z softmax, aby obliczyć logarytm prawdopodobieństwa próbki, otrzymamy:
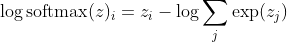
, co przy dużych różnicach w z przybliża się do
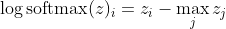
Najpierw widzimy tutaj składową liniową z_i. Po drugie, możemy zbadać zachowanie max (z) w dwóch przypadkach:
- Jeśli model jest poprawny, to max (z) będzie wynosić z_i. Zatem asymptoty logarytmiczno-prawdopodobieństwa zero (tj. Prawdopodobieństwo 1) z rosnącą różnicą między z_i a innymi wpisami w z.
- Jeśli model jest niepoprawny, to max (z) będzie jakimś innym z_j> z_i. Tak więc dodanie z_i nie znosi w pełni out -z_j, a log-prawdopodobieństwo jest z grubsza (z_i - z_j). To jasno mówi modelowi, co zrobić, aby zwiększyć logarytmiczne prawdopodobieństwo: zwiększyć z_i i zmniejszyć z_j.
Widzimy, że ogólne prawdopodobieństwo logarytmiczne będzie zdominowane przez próbki, w przypadku których model jest nieprawidłowy. Ponadto, nawet jeśli model jest naprawdę nieprawidłowy, co prowadzi do nasycenia softmaxu, funkcja straty nie ulega nasyceniu. Jest w przybliżeniu liniowy w z_j, co oznacza, że mamy mniej więcej stały gradient. Pozwala to modelowi na szybką korektę. Zauważ, że nie dotyczy to na przykład błędu średniokwadratowego.
Długie wyjaśnienie
Jeśli softmax nadal wydaje Ci się arbitralnym wyborem, możesz spojrzeć na uzasadnienie użycia sigmoidy w regresji logistycznej:
Dlaczego funkcja sigmoidalna zamiast czegokolwiek innego?
Softmax jest uogólnieniem esicy dla problemów wieloklasowych, uzasadnionych analogicznie.



