Muszę zweryfikować nazwę domeny:
google.com
stackoverflow.com
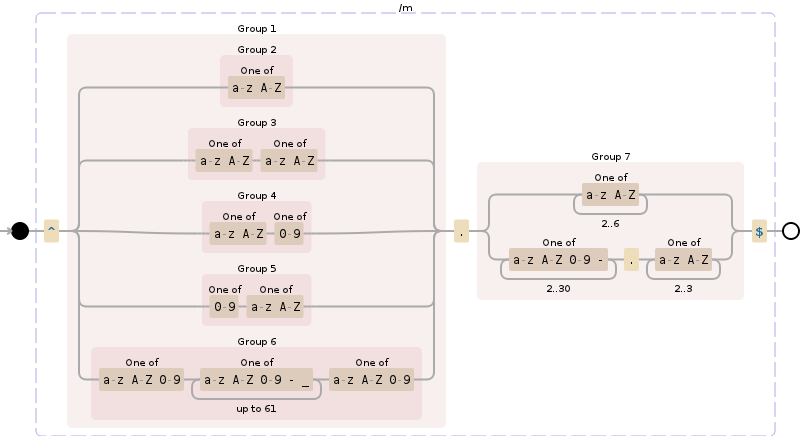
A więc domena w najczystszej postaci - nawet nie subdomena, jak www.
- Znaki powinny być tylko az | AZ | 0-9 i kropka (.) I myślnik (-)
- Część nazwy domeny nie powinna zaczynać się ani kończyć myślnikiem (-) (np. -Google-.com)
- Część nazwy domeny powinna mieć od 1 do 63 znaków
Rozszerzenie (TLD) może być na razie dowolne w ramach reguł nr 1, mogę je później zweryfikować na liście, jednak powinno to mieć 1 lub więcej znaków
Edycja: TLD ma najwyraźniej 2-6 znaków w obecnej postaci
Nie. 4 poprawiono: TLD powinno być właściwie oznaczone jako „subdomena”, ponieważ powinno zawierać takie rzeczy, jak .co.uk - wyobrażam sobie, że jedyna możliwa walidacja (poza sprawdzeniem na liście) to „po pierwszej kropce powinna znajdować się jedna lub więcej znaków zgodnie z zasadami nr 1
Bardzo dziękuję, uwierz mi, że próbowałem!
1
Może wcale nie być pomocne. Jeśli chodzi o google.co.uk i niektóre domeny japońskie, jestem pewien, że będziesz musiał dwa razy pomyśleć, zanim użyjesz do tego wyrażenia regularnego. Osobiście uważam, że regex nie wystarczy, aby zweryfikować domenę w prawdziwej domenie. Do Twojej wiadomości, tutaj jest prawie pełna lista adresów TLD i lista domen drugiego poziomu z kodem kraju: static.ayesh.me/misc/SO/tlds.txt
—
Ayesh K
Zobacz moją odpowiedź na powiązane pytanie dotyczące weryfikacji nazwy hosta .
—
SAM,
Często zapominane: w przypadku w pełni kwalifikowanych nazw domen należy dopasować kropkę po tld.
—
schmijos
Niektóre z tych odpowiedzi są całkiem dobre, ale jest też inna dobra odpowiedź na inne pytanie, której warto się przyjrzeć.
—
craftworkgames