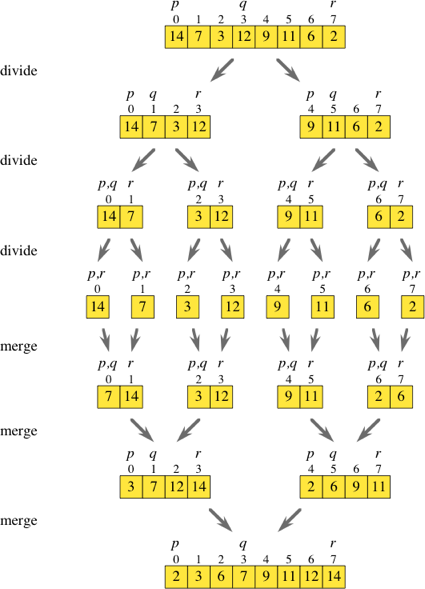
Więc scalanie to algorytm dzielenia i zdobywania. Kiedy patrzyłem na powyższy schemat, zastanawiałem się, czy można w zasadzie ominąć wszystkie kroki podziału.
Jeśli iterowałeś po oryginalnej tablicy podczas przeskakiwania o dwa, możesz uzyskać elementy o indeksie i i i + 1 i umieścić je w ich własnych sortowanych tablicach. Po uzyskaniu wszystkich tych pod-tablic ([7,14], [3,12], [9,11] i [2,6], jak pokazano na schemacie), możesz po prostu przejść do normalnej procedury scalania, aby uzyskać posortowana tablica.
Czy iteracja po tablicy i natychmiastowe generowanie wymaganych pod-macierzy jest mniej wydajne niż wykonywanie kroków podziału w całości?
Powiązane: cs.stackexchange.com/questions/77075/…
—
Omar