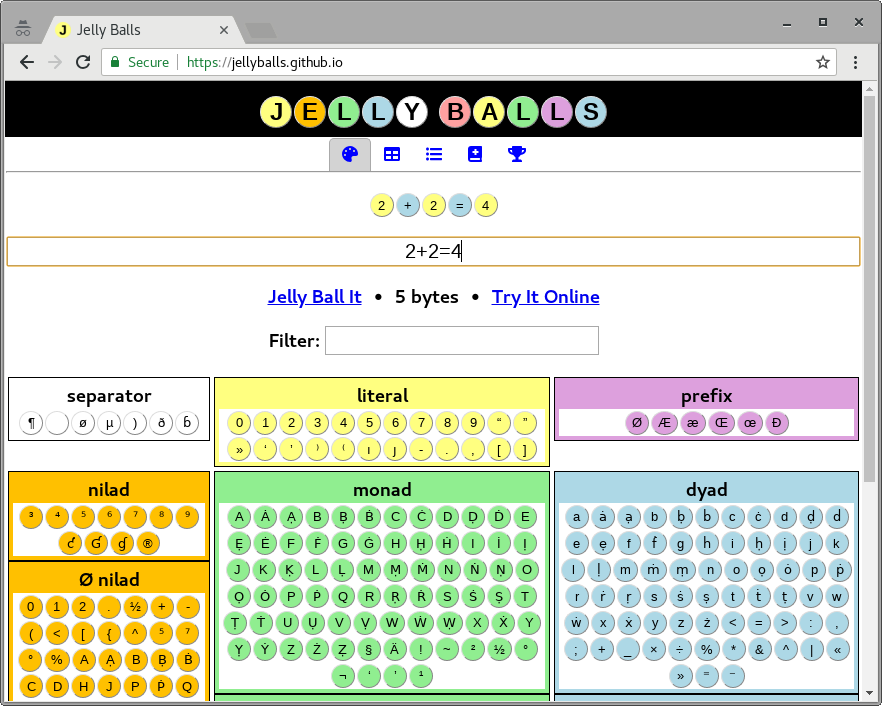
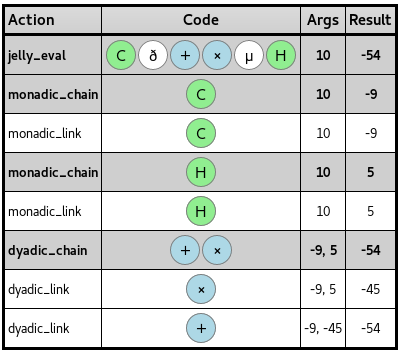
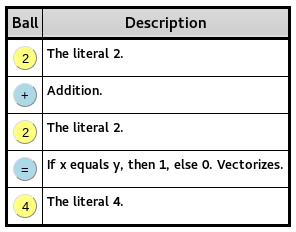
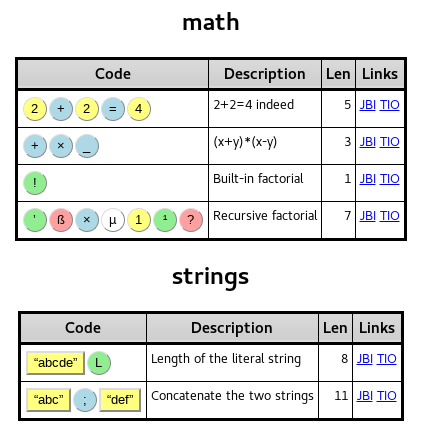
Lista poleceń i literałów
Jeśli spróbujesz użyć wielu poleceń listy bez wektoryzacji na literale n lub liście literałów z , polecenie listy najpierw skonwertuje się na jakąś listę, a następnie wykona polecenie na tej liście.
Te polecenia pojawiają się przy użyciu wywołań iterablefunkcji w jelly.py .
def iterable(argument, make_copy = False, make_digits = False, make_range = False):
the_type = type(argument)
if the_type == list:
return copy.deepcopy(argument) if make_copy else argument
if the_type != str and make_digits:
return to_base(argument, 10)
if the_type != str and make_range:
return list(range(1, int(argument) + 1))
return [argument]
Oto kilka niekompletnych list tego, co zrobią te polecenia listy.
Zawija się w listę
Najprostszy powrót z iterable aby zawinąć argument na listę i zwrócić ten, który ma zostać przetworzony przez funkcję. Dzieje się tak, jeśli argument nie jest już listą, jest łańcuchem, a iterableargumenty nie wymagają innych metod.
-------------------------------------------------------------------------------
| Command | Description | Process | Effect |
-------------------------------------------------------------------------------
| F | Flattens a list | 4953F -> [4953]F -> [4953] | Same as W |
-------------------------------------------------------------------------------
| G | Format a list | 4953G -> [4953]G -> [4953] | Same as W |
| | as a grid | | |
-------------------------------------------------------------------------------
| I | Increments | 4953I -> [4953]I -> <nothing> | Empty list |
-------------------------------------------------------------------------------
| S | Sums a list | 4953S -> [4953]S -> 4953 | Same as ¹ |
-------------------------------------------------------------------------------
| Ṭ | Boolean array, | 4Ṭ -> [4]Ṭ -> [0, 0, 0, 1] | n-1 zeroes, |
| | 1s at indices | | 1 at end |
-------------------------------------------------------------------------------
| Ụ | Sort indices by | 4Ụ -> [4]Ụ -> [1] | Yields [1] |
| | by their values | | |
-------------------------------------------------------------------------------
| Ė | Enumerate list | 4Ė -> [4]Ė -> [[1, 4]] | Yields [[1, n]] |
-------------------------------------------------------------------------------
| Ġ | Group indices | 4Ġ -> [4]Ġ -> [[1]] | Yields [[1]] |
| | by values | | |
-------------------------------------------------------------------------------
| Œr | Run-length | 4Œr -> [4]Œr -> [[4, 1]] | Yields [[n, 1]] |
| | encode a list | | |
-------------------------------------------------------------------------------
Konwertuj na bazę 10
Funkcje tutaj wywołują iterablekonwersję na liczbę na listę jej cyfrD , a następnie uruchamiają te cyfry.
-------------------------------------------------------------------------
| Command | Description | Process | Effect |
-------------------------------------------------------------------------
| Q | Unique elements | 299Q -> [2, 9, 9]Q -> [2, 9] | Unique |
| | ordered by | | digits |
| | appearance | | of n |
-------------------------------------------------------------------------
| Ṛ | Non-vectorized | 4953Ṣ -> [4, 9, 5, 3]Ṛ | Reverses D |
| | reverse | -> [3, 5, 4, 9] | |
-------------------------------------------------------------------------
| Ṣ | Sort a list | 4953Ṣ -> [4, 9, 5, 3]Ṣ | Sorts D |
| | | -> [3, 4, 5, 9] | |
-------------------------------------------------------------------------
Konwertuj na listę z zakresem
Funkcje tutaj konwertują liczbę na zakres R = [1 ... n], a następnie działają w tym zakresie.
-----------------------------------------------------------------------------------------
| Command | Description | Process | Effect |
-----------------------------------------------------------------------------------------
| X | Random element | 4R -> [1 ... 4]X -> 2 | Random element |
| | | | of R |
| | | | |
-----------------------------------------------------------------------------------------
| Ḋ | Dequeue from list | 4R -> [1 ... 4]Ḋ -> [2, 3, 4] | Range [2 ... n] |
-----------------------------------------------------------------------------------------
| Ṗ | Pop from list | 4Ṗ -> [1 ... 4]Ṗ -> [1, 2, 3] | Range [1 ... n-1] |
-----------------------------------------------------------------------------------------
| Ẇ | Sublists of list | 4Ẇ -> [1 ... 4]Ẇ | All sublists of R |
| | | -> [[1], [2], [3], [4], [1, 2], | |
| | | [2, 3], [3, 4], [1, 2, 3], | |
| | | [2, 3, 4], [1, 2, 3, 4]] | |
-----------------------------------------------------------------------------------------
| Ẋ | Shuffle list | 4Ẋ -> [1 ... 4]Ẋ -> [2, 1, 3, 4] | Shuffles R |
-----------------------------------------------------------------------------------------
| Œ! | All permutations | 3Œ! -> [1, 2, 3]Œ! | All permutations |
| | of a list | -> [[1, 2, 3], [1, 3, 2], | of R |
| | | [2, 1, 3], [2, 3, 1], | |
| | | [3, 1, 2], [3, 2, 1]] | |
-----------------------------------------------------------------------------------------
| ŒḄ | Non-vectorized | 4ŒḄ -> [1 ... 4]ŒḄ | Bounces R |
| | bounce, | -> [1, 2, 3, 4, 3, 2, 1] | |
| | z[:-1] + z[::-1] | | |
-----------------------------------------------------------------------------------------
| Œc | Unordered pairs | 4Œc -> [1 ... 4]Œc | Unordered pairs |
| | of a list | -> [[1, 2], [1, 3], [1, 4], [2, 3], | of R |
| | | [2, 4], [3, 4]] | |
-----------------------------------------------------------------------------------------
| Œċ | Unordered pairs | 4Œċ -> [1 ... 4]Œċ | Unordered pairs |
| | with replacement | -> [[1, 1], [1, 2], [1, 3], [1, 4], | with replacement |
| | of a list | [2, 2], [2, 3], [2, 4], [3, 3], | of R |
| | | [3, 4], [4, 4]] | |
-----------------------------------------------------------------------------------------
| ŒP | Powerset of | 3ŒP -> [1 ... 3] | Powerset of R |
| | a list | -> ['', [1], [2], [3], [1, 2], | |
| | | [1, 3], [2, 3], [1, 2, 3]] | |
-----------------------------------------------------------------------------------------
| Œp | Cartesian | 4,2Œp -> [[1 ... 4], [1 ... 2]]Œp | Cartesian product |
| | product of z's | -> [[1, 1], [1, 2], [2, 1], [2, 2], | of [1 ... z[i]] |
| | items | [3, 1], [3, 2], [4, 1], [4, 2]] | for i in z |
-----------------------------------------------------------------------------------------