Myślę, że najlepiej będzie, jeśli rozwiążę twój drugi punkt, przykładowym ruchem w grze 1 między AlphaZero i Sztokfiszem, który również zaspokoił moją ciekawość dzisiaj.
limit 1 min / ruch (w jaki sposób miałaby to niekorzystna cecha Sztokfisz?)
Wydajność Sztokfiszu zależy zarówno od limitu czasowego, jak i konfiguracji sprzętowej, więc pomyśl tylko, kiedy ktoś podwaja wątki procesora, wtedy Sztokfisz potrzebuje mniej czasu (niekoniecznie o połowę), aby znaleźć rozwiązanie, niż w przypadku pierwszej konfiguracji.
W pierwszym raporcie opublikowanym na Chess.com ktoś twierdził, że Sztokfisz nie gra optymalnie, ponieważ nie może odtworzyć tych samych wyników przy użyciu tego samego Sztokfisza na swoim komputerze. Powiedział, że na poniższej pozycji (gra 1 - ruch 11) Sztokfisz zagrał Kg1-h1 (przesunął swojego króla), co nie miało żadnego sensu. Z drugiej strony sztokfisz na swoim komputerze pokazał bardziej rozwijający się ruch jak Be3 (ruch ciemnego kwadratu biskupa), spójrzmy na pozycję:
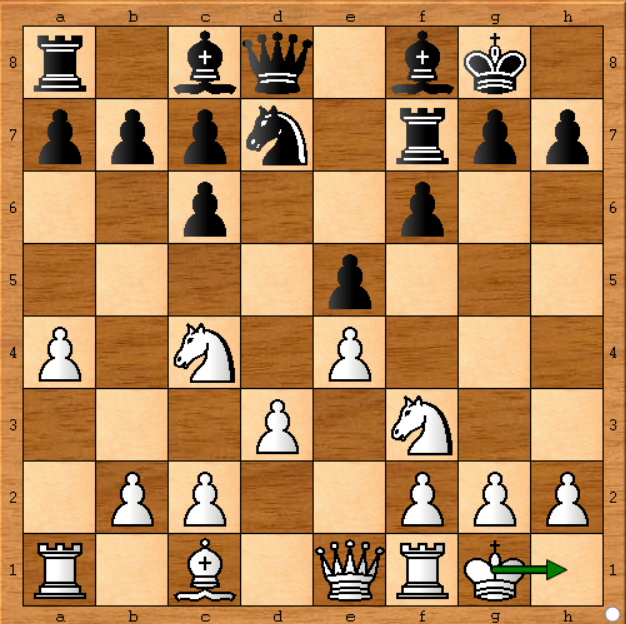
Tak, był to ruch pasywny i wydaje się, że Sztokfisz powinien był grać bardziej rozwijający się ruch. Ale się mylił. Czemu? Ponieważ prowadził Sztokfisz przez 15 sekund, a gdyby uruchomił go przez godzinę, otrzymałby Kg1-h1 jako najlepszy ruch w tej pozycji. Sztokfisz zmienia swoją decyzję, analizując głębiej wszystkie możliwe ruchy. Oto, co pierwotnie powiedziałem w mojej odpowiedzi :
Uruchomiłem najnowszego sztokfisza na pozycji (w ruchu 11):
- Na początku daje b4 jako optymalny ruch, gdy silnik pracuje przez około minutę. Następnie decyduje, że Be3 jest lepszy.
Ale po 5 minutach na moim sprzęcie, który działa na 1400k węzłów / s, zdecyduje się na Kh1 jako optymalny ruch.
W artykule jest powiedziane, że sztokfisz oblicza 70 000 000 pozycji na sekundę i jest uruchamiany przez 1 minutę na ruch, czyli około 50 razy więcej niż mój sprzęt, więc pozwolę mojej kopać przez 50 minut ... Kg1-h1 wciąż jest wybór dla Sztokfisz.
Kluczem jest limit czasu
W powyższym przypadku prawdopodobnie nie miało większego znaczenia, jeśli Sztokfisz biegał dwa razy, ponieważ decyzja byłaby taka sama, ale przy następnym ruchu zdecydowanie :
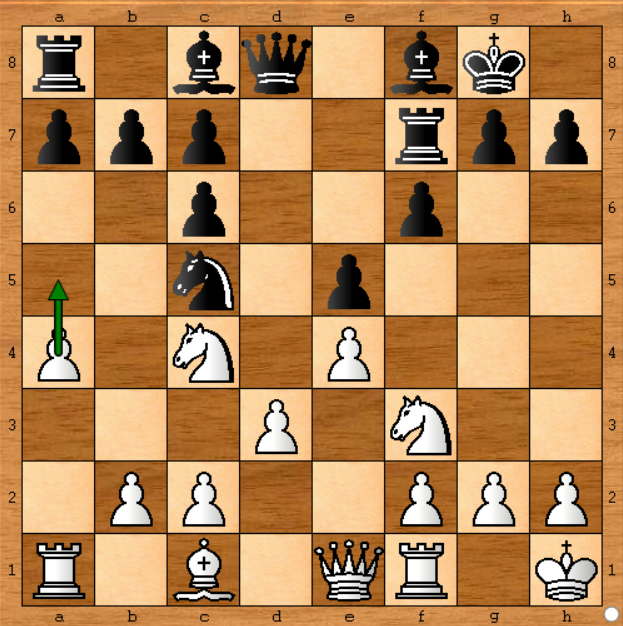
W tej pozycji Sztokfisz postanowił przesunąć pionka po lewej stronie ( a4-a5 ). Załóżmy, że mam komputer z silnikiem Sztokfisz z prędkością 1400 tys. Węzłów na sekundę, czyli około 50 razy mniej niż Sztokfisz w prawdziwej grze ( w gazecie napisano 70 000kn / s). Mogę więc symulować grę, jeśli uruchamiam ją przez 50 minut przy każdym ruchu. W porządku.
Przeprowadziłem analizę Sztokfisz na powyższej pozycji i uzyskałem następujące wyniki:
- Sztokfisz zaczął od sugerowania pewnych ruchów, ale po 6 minutach na moim komputerze (co odpowiada 7,2 sekundy na Sztokfiszu w prawdziwej grze) wolał a4-a5, tak jak gra .
To dobrze, ale utrzymywałem go przez pełne 50 minut, aby dotrzeć do obliczeń Sztokfisz w grze, która była dozwolona przez 1 minutę:
Smutna prawda jest taka, że uważam, że Sztokfisz przegrał wszystkie swoje gry z powodu limitu czasu. Sztokfisz staje się coraz bardziej dogłębnie wyszukiwany i oceniany w miarę upływu czasu, aw grze nie wolno było używać książki otwierającej, co powoduje, że rozważa wiele ruchów na płytkich głębokościach. Zauważ, że w rzeczywistej grze rozegrano a4-a5, co pokazuje, że (zakładając, że może ona ocenić 70 milionów pozycji na sekundę) Sztokfisz w grze nie spędził więcej niż 21,6 sekundy w ruchu. W przeciwnym razie zmieniłby decyzję na te trzy inne ruchy w grze. Powód tego jest wciąż dla mnie niejasny, ponieważ mój Sztokfisz również zużywał mniej pamięci (około ~ 130 MB pamięci RAM w porównaniu z 1 GB wspomnianym w oryginalnym artykule , zakładając, że wszystko to trafia do tabel skrótów).
Wniosek
Sprzęt, na którym działał Sztokfisz, jak wskazałem, był co najwyżej 18 razy szybszy niż mój (aktualizacja: na jednym rdzeniu) w oparciu o analizowany przeze mnie ruch. Nie jestem pewien, czy AlphaZero naprawdę mógłby wykorzystać taki sprzęt do szkolenia swoich sieci w ciągu 4 godzin, mogę tylko założyć, że jest zbyt niski dla gry takiej jak szachy. Poza tym AlphaZero spędził te godziny na nauce, która obejmuje także budowanie solidnych otworów (i jak wskazuje dokument, preferencje w stosunku do niektórych otworów). Z drugiej strony Sztokfisz był upośledzony w otworach i nie oceniał 70 milionów pozycji na sekundę przez 60 sekund przy każdym ruchu.
Na koniec, wszystko, co powiedziałem, opierało się na moich założeniach. Oczywiście wyniki AlphaZero i gier były dla mnie bardzo interesujące. Chciałbym jednak zobaczyć grę, w której gra Stockfish była taka sama, jak na moim komputerze. Oznacza to, że dozwolony jest więcej czasu i książka otwierająca. Łatwo jest również uzyskać wyniki analizy Sztokfisz przy każdym ruchu i chciałbym, aby ją wypuścili, aby pokazać, jak dobrze się spisała.